Mutagenesis and Genomics Team Homepage ver1.2 [to Japanese Page]
Research Objectives of Mutagenesis and Genomics Team
Our main objective is to elucidate the biological information in the genomic DNA sequences and ultimately to understand the life system. We focus on mutations in the genomic DNA sequences. Mutations have generated genetic variability in species and eventually have been driving evolution. Such genetic variabilities within species are recognized as polymorphisms, in particular, which are called single nucleotide polymorphisms (SNPs) if the changes encompass single base-pair mutations. The genetic variability eventually causes speciation and drives evolution.
Mutations, on the other hand, usually have detrimental effects on organisms. Mutagenesis thus has been developed together with risk assessment tests of genotoxic agents like radiations, oxidative stresses and mutagenic chemicals that are occasionally tightly linked to the tumorigenesis, senescence and other genetic diseases. In other words, the understanding of mutations and mutation effects is the key to prevent, diagnose and cure such genetic diseases and to improve the quality of life (QOL) dependent on personal physical constitutions.
To achieve our research objectives, we develop research platform that allows us to directly connect "DNA-base changes" and "biological differences", namely, genotype and phenotype. We primarily take genetic approach for this purpose. Geneticists has been mainly tackling each mutation one by one. Now we develop a high-throughput and robust genetics in a large scale. This is a new information biology, which we call "the Renascence of Classical Genetics".
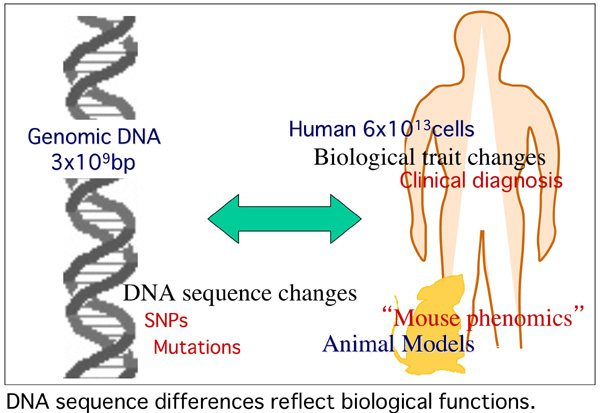
Based upon the discovery of the DNA structure by Watson and Click, it is the current paradigm that all the blueprint of the life is depicted in the genome sequences. To decipher the life system,deductive methods have been undertaken; from genome sequences to genes, transcriptions, proteins, organelles, cells, tissues, organs, organisms and populations. As a matter of course, it encounters the astronomical scale of complicated molecular and cellular networks in the life system. There is a way, however, to directly connect the function of a single base-pair of genome sequences to the life system by bypassing all the molecular and cellular labyrinths. “MUTANT” provides an ultimate tool as a bona fide biosimulator for the functional annotation of gene and genome networks. Genetics, with mutations and mutants, has been elucidating the life system. By constructing a large-scale database (DB) for genotypes and phenotypes in genome-wide manner, it becomes feasible to elucidate the biological function of the genome.We have been establishing such DBs for the mouse mutagenesis as a model system.
1. Mutagenesis and genomics research.
The life is phenomena of spatiotemporally-regulated material flows. Proteins as enzymes control the flows called metabolism. Proteins are, thus, the blueprints per se. The primary structures of proteins coded in the part of the genome, however, do not implicate the whole life system. It is necessary to decode the genome information where, when, how much and what conditions the proteins are expressed. To elucidate the dynamic mechanisms of genome function, we apply genetic approaches to directly associate genomic DNA sequences to individual phenotypes by using mutations and mutants.
1-1. Development of a large-scale phenotype database
The phenotype DB for the mouse mutagenesis project has so far compiled the total volume of 2 million data by screening 200 traits of approximately 20,000 G1 mice which have been derived from the ENU treated male parents (G0). It mainly encompasses the dominant phenotypes. The accumulation of recessive ones have been also underway, in particular, in the course of phenotype analyses of mutants obtained by the ENU-based gene-driven mutagenesis.
1-2. Development of a large-scale genotype database
By the gene-driven mutagenesis system, more than five hundred point mutations have been identified from the ENU-mutagenized G1 genomic DNA archive. The further high throughput discovery had been achieved by the multiplexing the Temperature-Gradient Capillary Electrophoresis (TGCE) method. In addtion, we are developing and detecting novel ENU-induced mutations by the TILLING/Cel1 or High Resolution Melt (HRM) methods. Forseeing the coming next-generation sequencer or "$1000 re-sequencing system", we also conduct some feasibility studies to directly identify all the ENU-induced muations by such new technologies. Based upon the availability of genome sequence databases both for human and mouse, we have started the search of highly conserved nongenic sequences that well likely to code for the dynamic regulations of the genome function.
1-3. Development of integrated knowledge-database
The ultimate goal of the construction of a large-scale phenotype DB and genotype DB is to understand the biological function of the genomic sequences. The mouse model has well advanced. In particular, we have been developing mapping tools for the identification of phenotype-driven mutagenesis. Collaborative researches: Development of mapping methods in the detection of causative genes in animal and plant mutagenesis. Development of a procedure for identification of mutant genes by the integration of genome information in mouse. Concerted efforts among multidisciplinary researchers and communities synergistically develop a new information biology based upon classical genetics.
since 2008.8.26
Copyright(C)2008-2010 RIKEN BioResource Center, Japan. All rights reserved.